
Содержание (1) Введение (2) Этапы работы, визуализация данных (3) Вывод (4) Описание применения генеративной модели
ВВЕДЕНИЕ
Итоговый проект стал для меня возможностью провести анализ данных по интересующей меня теме, создав при этом визуализацию для отработки навыков в применении искусственного интеллекта. Выбранная мною тема — «Diabetes prediction dataset» или «Набор данных для прогнозирования диабета», которые я нашла предложенном в приложении к заданию сайте Kaggle. Более года назад я активно стала интересоваться изучением своего организма, его реакциями и тем, какие привычки на сегодняшний день уже оказывают влияния на мое будущее. Я стала активно заниматься своим здоровьем: режимом сна, пищевыми привычками — образом жизни в целом, видя рядом с собой людей с разными распространенными заболеваниями, в том числе и сахарным диабетом, которые крайне страшны в своем проявлении. Именно поэтому, увидев данные содержащие набор медицинских и демографических данных от пациентов, с наличием или отсутствием данного заболевания: возраст, пол, индекс массы тела (ИМТ) и др.; мне стало интересно проанализировать то, какие факторы влияют на развитие и протекание болезни и влияют ли они вообще? В своем проекте я использовала следующие типы графиков: 1)Столбчатая диаграмма 2)Гистограммы 3)Bubble Chart 4) Pie Chart
ЭТАПЫ РАБОТЫ, ВИЗУАЛИЗАЦИЯ ДАННЫХ
1 шаг
С помощью нейросети Ideogram ai я создала обложку для проекта написав promt: «A detailed and informative medical illustration depicting the process of diagnosing diabetes. A doctor, wearing a white coat and stethoscope, is examining a patient who has a blood sample taken from their arm. A small bottle labeled „glucose“ captures the sample, while a digital screen shows the blood sugar levels. The background features medical instruments and diagrams, conveying the complex nature of the disease. The overall tone of the illustration is educational and comprehensive., illustration»
2 шаг
import pandas as pd
import numpy as np import pandas as pd import matplotlib.pyplot as plt
Я открыла Google Colab и написала в первой ячейке следующее: import pandas as pd: эта строка импортирует библиотеку pandas и присваивает ей сокращенное имя pd;
import numpy as np: эта строка импортирует библиотеку numpy и присваивает ей сокращенное имя np. Numpy — библиотека для работы с массивами и матрицами в Python;
import matplotlib.pyplot as plt: эта строка импортирует библиотеку matplotlib.pyplot и присваивает ей сокращенное имя plt. matplotlib — библиотека для создания графиков и визуализации данных. Pyplot — подмодуль, предоставляющий удобный и простой интерфейс для создания различных типов графиков.
3 шаг
df = pd.read_csv ('diabetes_prediction_dataset.csv') df
Создаем переменную df, которой мы присваиваем значение функции pd.read_csv, считывающей данные из CSV-файла diabetes_prediction_dataset.csv.
На выходе мы получаем таблицу — переменную df, которая содержит DataFrame с полученными на вход данными.
4 шаг
Теперь переходим к поиску лучших комбинаций анализируемых данных для создания визуализации.
Создаем столбчатую диаграмму о сопоставлении отдельно женского пола и их возраста и отдельно мужского пола и их возраста, чтобы проанализировать то, в каком возрасте мужчины и женщины чаще всего болеют сахарным диабетом.
female_df = df[df['gender'] == 'Female'] male_df = df[df['gender'] == 'Male']
fig, (ax1, ax2) = plt.subplots (nrows=1, ncols=2, figsize=(12, 4))
ax1.hist (female_df['age'], bins=8, edgecolor='#ab3a3f', color='#ab3a3f') ax1.set_title ('Diabetic women') ax1.set_xlabel ('age') ax1.set_ylabel ('Number of respondents')
ax2.hist (male_df['age'], bins=8, edgecolor='#ab3a3f', color='#ab3a3f') ax2.set_title ('Diabetic men') ax2.set_xlabel ('age') ax2.set_ylabel ('Number of respondents')
plt.show ()
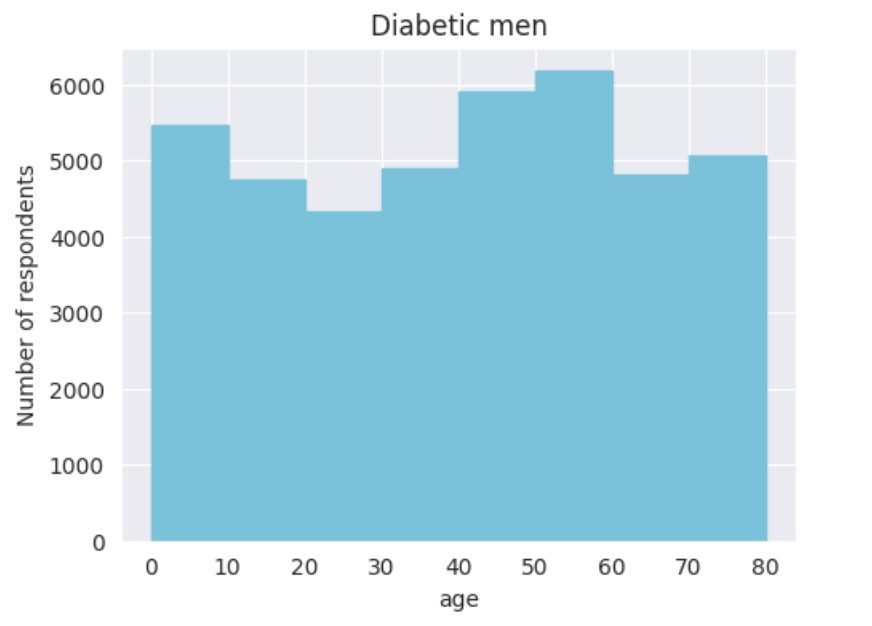
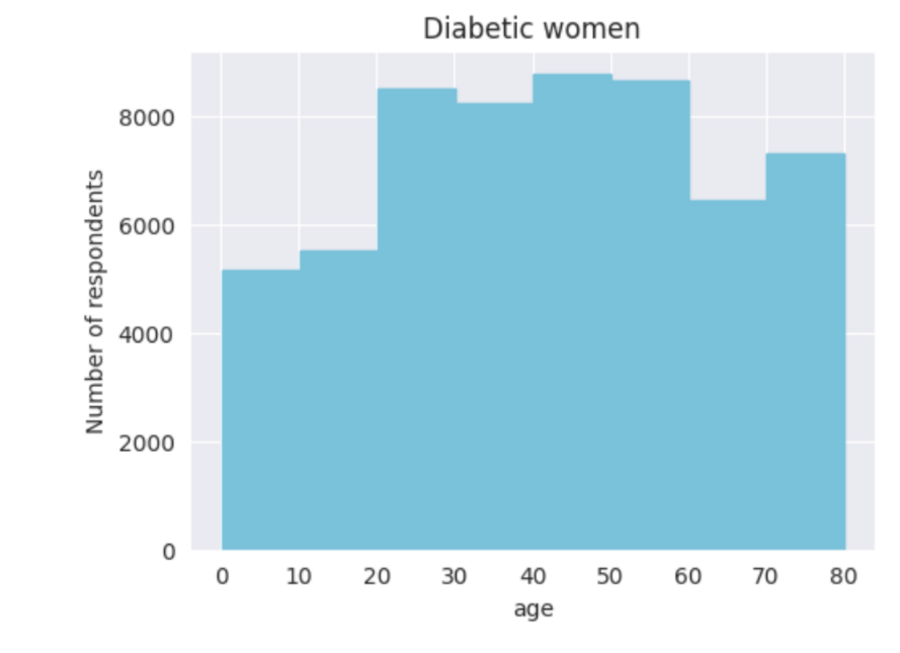
Затем, создаю график Bubble Chart, который покажет то, какой показатель уровня глюкозы наиболее характерен для людей с диабетом и без него.
diabetic = df[df['diabetes'] == 1]['blood_glucose_level'] non_diabetic = df[df['diabetes'] == 0]['blood_glucose_level']
plt.figure (figsize=(8, 6)) plt.scatter ([0] * len (diabetic), diabetic, color='#60c3dd', label='Diabetic') plt.scatter ([1] * len (non_diabetic), non_diabetic, color='black', label='Non-Diabetic')
plt.xlabel ('Diabetes Status') plt.ylabel ('Blood Glucose Level') plt.title ('Blood Glucose Levels of People with and without Diabetes') plt.xticks ([0, 1], ['Diabetic', 'Non-Diabetic']) plt.legend ()
plt.show ()
diabetes_patients = df[df['diabetes'] == 1] non_diabetes_patients = df[df['diabetes'] == 0] mean_age = diabetes_patients['age'].mean () mean_hypertension = diabetes_patients['hypertension'].mean () mean_heart_disease = diabetes_patients['heart_disease'].mean () mean_bmi = diabetes_patients['bmi'].mean () mean_hba1c = diabetes_patients['HbA1c_level'].mean () mean_blood_glucose = diabetes_patients['blood_glucose_level'].mean () fig, ax = plt.subplots (figsize=(10, 6)) x = ['age', 'hypertension', 'heart_disease', 'bmi', 'HbA1c_level', 'blood_glucose_level'] y = [mean_age, mean_hypertension, mean_heart_disease, mean_bmi, mean_hba1c, mean_blood_glucose] ax.bar (x, y, color='#60c3dd') ax.set_title ('Average rates for patients with diabetes') ax.set_ylabel ('Numeric value') plt.xticks (rotation=45) plt.show
Гистограмма показывает то, какие показатели наименее и наиболее ярко проявляются у людей с заболеванием диабет.
smoking_diabetes = df.groupby (['smoking_history', 'diabetes']).size ().unstack (fill_value=0)
print («Доля пациентов с диабетом среди курящих:», smoking_diabetes.loc['current', 1] / smoking_diabetes.loc['current'].sum ()) print («Доля пациентов с диабетом среди некурящих:», smoking_diabetes.loc['never', 1] / smoking_diabetes.loc['never'].sum ())
diabetes_patients = df[df['diabetes'] == 1] plt.figure (figsize=(6, 6)) labels = diabetes_patients['smoking_history'].unique () sizes = [len (diabetes_patients[diabetes_patients['smoking_history'] == label]) for label in labels] colors = ['#60c3dd', '#30b0d1', '#0097b2'] plt.pie (sizes, labels=labels, colors=colors, autopct='%1.1f%%') plt.title ('Распределение пациентов с диабетом по статусу курения') plt.axis ('equal') plt.show ()
ВЫВОД
Выполняя проект по анализу данных и их визуализации, я не только закрепила свои знания в программировании на языке Python, но и улучшила свои навыки в использовании нейросетей, которые сейчас являются крайне востребованы, благодаря своему широкому применению и высокой эффективности.
Я проанализировала данные по теме диабета, что дало мне больше знаний в области зарождения диабета как одной из самых распространенных заболеваний. А знания в области программирования дали возможность создать качественную визуализацию для лучшей обработки и запоминания информации, которая поможет мне и моей семье предотвратить появление диабета или как минимум снизить риск его появления.
ОПИСАНИЕ ПРИМЕНЕНИЯ ГЕНЕРАТИВНОЙ МОДЕЛИ
Для создания обложки проекта использовала ИИ. Изображение сгенерировано в Ideogram. https://ideogram.ai/t/explore
Для генерации оттенков, применяемых в визуализации данных, использовала сервис gradients.app. https://gradients.app/ru
DATASET



